

Michael: Gee, it is my business model. I mean, if you had a business model, then by all means, you go in there and do…
For the last few weeks, frantic liberals have been checking the 538 election forecasts, and discovering a lot of reasons to worry. Their model – which famously predicted a relatively easy win for Obama in 2012, against the wisdom of pundits who insisted it was a 50/50 election – dropped Clinton down into the 60s at the start of November, and only finally ticked slightly back over 70 last night.
This compares to a host of other models, which have all consistently put the race in the 80s and 90s – a virtually sure thing.
Meanwhile, Silver has been quite pugilistic with his critics, making two key arguments. First, predictions are difficult and our knowledge imperfect. Our models ought to incorporate that doubt, something that he thinks the other forecasting systems don’t do enough of. Second, drawing on information sources outside of a systematic model introduces bias. People will cherry-pick information that matches their desires, and the introduction of that bias will pollute the conclusions.
What Nate Silver gets right about forecasting
Both of these arguments have value, and deserve attention. Models are only as smart as the work that we put into them. They organize information, providing stable techniques for analyzing and unfolding the meaning contained in the data. But all the assumptions of the model are the assumptions WE humans generate. And there’s good reasons for us to be skeptical about the quality and reliability of our guesses.
Which is to say: broadly speaking, Silver is right to encourage us to frame our thoughts through rigorous models, but also right to remind us that rigor is not the same thing as certainty.
However, and it’s a big however, threading the needle between those two premises can be difficult. And Silver has definitely failed to execute it perfectly in this cycle. In part, this seems driven by his notable failure in the Republican primary, where he famously declared Trump had virtually no chance. Of course, so did many others (including your humble blogger here), so that’s hardly a specific fault of Silver’s. But regardless, the experience seems to have left him a little snakebit. In his autopsy of that prediction, Silver noted that the basic error was one of punditry – shooting from the hip based on anecdote and guesswork, rather than constructing and then trusting a systematic model. And there’s some truth to that, as I’ve just explained. But there’s also a serious risk of overcorrection.
Remember: models only produce useful information to the extent that we build them on solid foundations. That means that good analysis often requires both assessing what the model tells us, and then assessing what information it might be failing to capture.
What’s ‘missing’ from the 538 model
In the 2016 presidential election, there are a few crucial pieces of information that 538’s model doesn’t include, which someone interested in improving the science of forecasting should care about a great deal.
First, the model doesn’t ‘know’ anything about turnout operations. The political science here is scattered, and mostly suggests that turnout has relatively little effect. But ‘little’ isn’t the same as zero. Particularly when one campaign is a well-oiled machine and the other is, to put it politely, a dumpster fire.
It’s important to note that 538 makes no claim to incorporate this sort of information. Nor should it. Turnout probably does matter, but given our current state of knowledge, it would be wrong to suggest we have the tools to meaningfully incorporate it into a rigorous system. So this isn’t a knock on the model, per se; it’s just a reminder that ‘unmeasurable’ is not the same thing as ‘nonexistent.’
Second, the model doesn’t ‘know’ anything about other forecasts. This is a big deal. Research has shown that the ‘wisdom of crows’ holds with forecasters, as much as it does with polls themselves. Just like you shouldn’t remove outlier polls, you shouldn’t remove outlier forecasts. But it’s important to place them in context. And the context of 2016 makes clear that 538 is a fairly significant outlier. Does that mean that Silver’s model is wrong or broken? Of course not. It might end up being the most accurate! But a good forecaster will acknowledge the questions raised by their outlier prediction, even if they believe that their method is in fact the best one.
And that’s something that 538 hasn’t made particularly clear. When they talk about other models, it’s usually in terms of ‘who’s right’ but rarely (if ever) is the meta point made that averaging the results might well be more accurate than any single model. And in all other discussions, the background assumption of all their commentary is that the 538 model is a true representation of the state of the race.
But this is antithetical to the principles I described above: which suggest caution and humility as the benchmarks of good predictions. Silver has every right to be proud of his system, and should do his best to explain why his assumptions are superior. But he also ought to do a better job of communicating the risks of overreliance on any single model.
Third, and from my perspective most important, the model doesn’t ‘know’ how to process two durable and persistent features of the public polling: a stable Clinton advantage and a large number of ‘undecided’ voters.
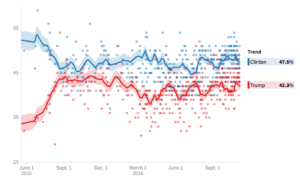
You can see both of these in the Pollster trendline, which shows A) a clear and unbroken Clinton edge and B) percentages for Clinton and Trump that add up to quite a bit less than 100%.
What is uncertainty, actually?
From Silver’s perspective, this adds a great deal of uncertainty to the race. A three-point lead of 51-48 is very hard to overcome, since one candidate already has a majority of the votes. A three-point lead of 45-42 is much less safe, because it doesn’t require flipping voters to make up the gap. So, in his model, Clinton’s persistent lead is interesting, but doesn’t indicate all that much safety.
And if those voters really were undecided, that would probably be true. What I’ve increasingly come to believe about this election, however, is that ‘undecided’ is a poor way to describe that missing 10-15%. I think that very FEW of them are genuinely undecided.
Instead, these folks are relatively strong partisans who don’t like the candidate their side is running and would prefer not to vote for them. And as long as the election remains far off, or looks like a blowout, they’ll remain on the sidelines. But when things seem to be getting close, they grudgingly fall in line.
The ‘Clinton wall’ hypothesis
I’ll be the first to admit that I lack a rigorous model to undergird this theory. But it strikes me as exceptionally plausible, and conforms quite nicely with the available facts. This theory suggests that ‘not Trump, dear god not Trump’ is an incredibly stable majority opinion among the electorate, with a significant subset who’d prefer to avoid casting a ballot for Clinton if they can avoid it. And it hypothesizes that anytime Trump draws close in the polling, a number of these leaners will fall in line to buttress the ‘Clinton wall.’
And that’s precisely what we see. Trump has bounced off that Clinton wall quite a few times. That’s partly due to the cycles of the campaign (the convention, the debates, the traditional unveiling of sexual assault tape), but it’s also likely an underlying feature of the electorate itself.
Silver built a model designed to look at undecided voters and extrapolate uncertainty. Given the parameters he set, newer polls matter more than older ones, and they establish trendlines for filtering other information. Those are perfectly reasonable assumptions. But other models don’t approach the question the same way. They take older polls as setting some important Bayesian priors about electoral attitudes.
Those models see a race where one candidate has led from start to finish and interpret ‘tightening’ in the polls as the normal ebbs and flows of a fundamentally exceptionally stable campaign. They are therefore a lot more CERTAIN about the strength of Clinton’s lead.
The problem isn’t punditry; the problem is bad punditry
Who is right? We’ll have to wait to see, and might not know even after the result are in. After all, everyone is predicting a Clinton win, and the difference between 70% and 90% simply isn’t going to come out in a single wash cycle. And chances are extremely high that no one is really ‘right’ here. Because that’s not how most science works. Our models are rarely correct. They’re just approximations, given what we knew at the time. As we get more information, and encounter new unexpected scenarios, we try to refine and improve our predictions.
And that’s been the real problem with 538 this cycle. There’s nothing ‘wrong’ with the model. It may in fact be the most accurate! But there has been something wrong with Silver’s attitude toward this kind of criticism. Faced with this sort of error, he’s tended to retreat into the bunker, more invested in defending the legitimacy of his assumptions than he is in improving the quality of forecasting in general.
That’s perhaps understandable, given the monetary incentives that drive the forecasting business, and given his desire to avoid another embarrassing incident of underselling Trump’s chances. After all, it’s easy to default back to the model, and to refuse to speculate much beyond what it tells us. But that’s a form of intellectual laziness, and one that doesn’t acknowledge that one of Silver’s greatest strength has always been his ability to blend data and analysis. That’s a crucial skill, and it’s one he’s been letting atrophy a bit, in favor of playing the role of iconoclast and destroyer of ‘conventional wisdom.’
So, if his mistake in the primary was to ‘act like a pundit,’ he hasn’t really fixed the problem. He’s doing less ‘pundit-like’ speculation, sure, but he’s replaced it with a different sort of punditry: where people take a baseline set of information with which they feel comfortable, and then do their best to minimize and ignore everything else.
In effect, Silver is behaving a little like the crusty old sportswriters he’s always criticized: certain that the stats they know tell the whole story, and nothing else is deserving of their attention. The 538 forecast is a heck of a lot better than batting average and game-winning-RBIs, of course, but it still needs improvements. And it’s more likely to get those improvements if it’s understood as a technique for assisting analysis, rather than as a form of analysis itself.